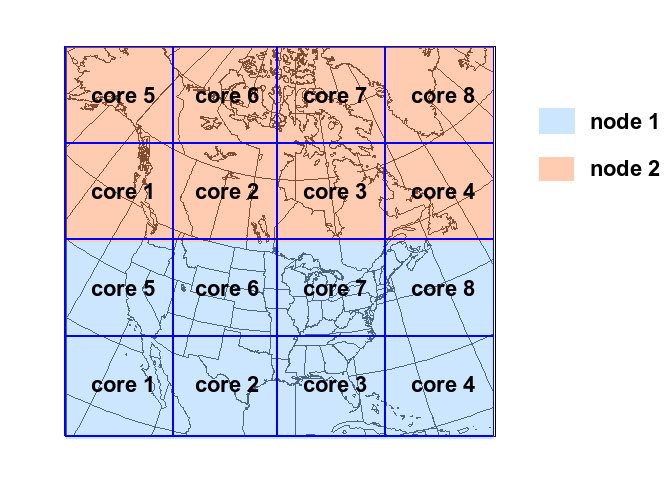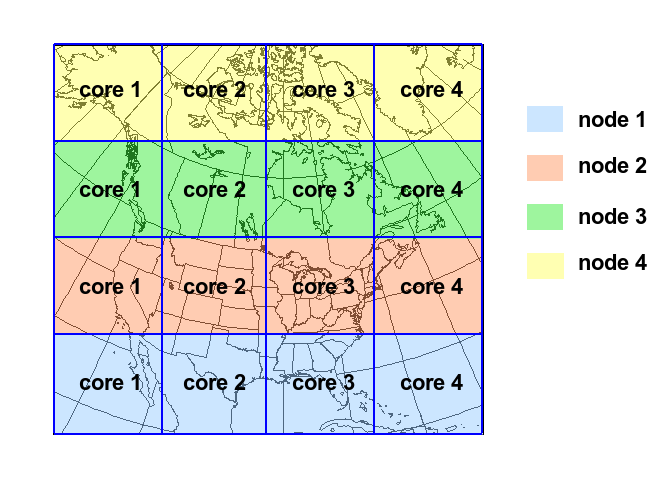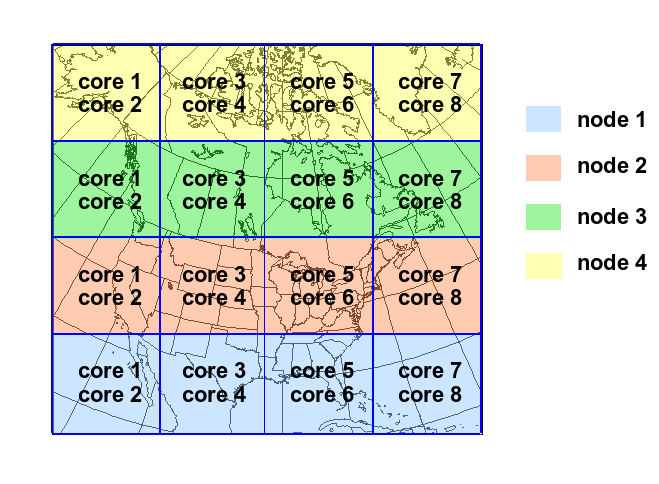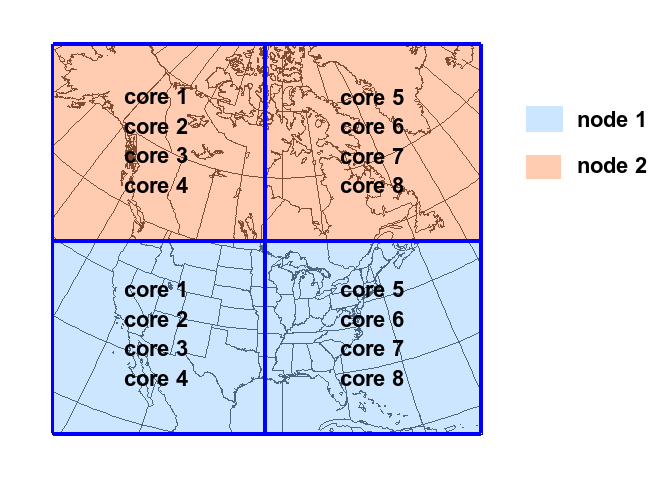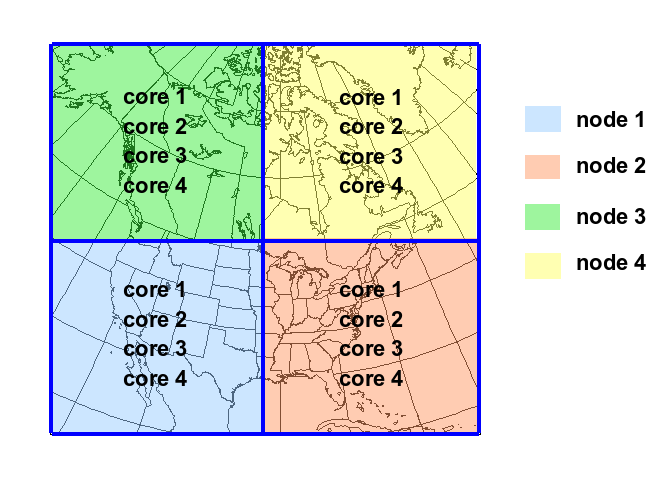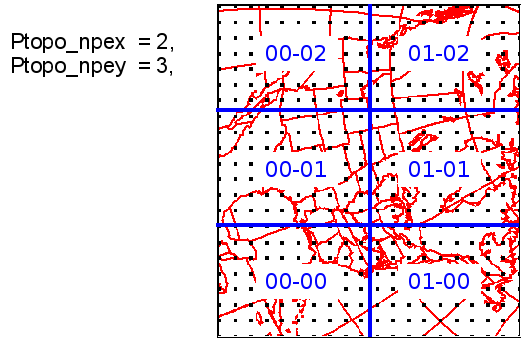
When running a global grid, uniform or stretched, insure that you have as little as possible divisions in x-direction. That means keeping 'Ptopo_npex' small and rather increase 'Ptopo_npey'. Some calculations in the model work very well in x-direction when not cut (near the poles).
Also have a look at the general introduction to GEMDM.